
Donate
 CC BY NC SA 4.0 (Unless specified)
CC BY NC SA 4.0 (Unless specified) 注:本文的撰写日期为2023/02/15,反映了作者对当下ChatGPT发展现状的认识以及思考,不代表其观点具有长期的有效性。
ChatGPT,Apprentice Bard, Bing-Chat,这些词逐渐成为了社会关注的焦点,就如同几年前比特币和相关的Cryptocurrency成为了Nerd圈口中放不下的包袱一样。 对于一部分人来说,这或许意味着AI产业爆发出的新兴力量,亟待开拓和投资;对于普通人来说,或许他们还没能感受到ChatGPT对其生活的影响,但是也已经不远了;对于本文的作者来说,这是一个关键的时间点:ChatGPT目前处于一个介于Scholar Interpretation和Real-life Implementation之间的关键时间点,对其现实生活中使用时的很多可能的影响已经能够看到和预测到。本文站在一个信息疫情、媒体、社会科学、历史等多学科研究者的视角,对ChatGPT的发展及其可能引发的问题、AI对人类影响的两个闭环、AI信任危机等话题进行讨论。
一本正经的胡说八道及其根源
ChatGPT进入Developer test阶段已经有了几个月,相信已经有不少人通过各种渠道测试了ChatGPT的功能,不管是官方渠道,还是反向工程的API,抑或是类似于Merlin的Chrome插件。很多人,尤其是计算机相关的职业工作者,或是类似于Linus、Tom Scott之类的Influencer,对ChatGPT赞不绝口,尤其是其对编程的熟练程度。甚至已经有一些人开始使用ChatGPT编写Chatbot,比如sentdex。
本文作者对ChatGPT的能力也测试过一些,尤其是其在学术写作上的帮助是绝大的。使用ChatGPT来修正自己的文案,让ChatGPT帮助自己转换参考文献格式,甚至撰写简单的程序,以及解释Github上刚fork下来的code,这些都使得作者的工作效率有了显著的提升。

ChatGPT对一段程序的解释 比如上面这张图的例子。看到这个结果的时候,我和Tom Scott一样,也感觉到了一种从脊梁骨向上翻腾的寒气和不安感。对于一个程序,ChatGPT几乎能够一丝不差的将程序的变量、参数,甚至功能和效果解释的一清二楚,耗时不超过20秒。让人最惊叹的并不是其对变量和函数的解释,而是其最后的一句话“程序中的这些函数可以帮助用户在使用WebVPN时更方便地访问受限制的网站。” 没人在注释中给出过这种解释,没人告诉你这个程序有啥用处!也就是说,ChatGPT不止可以理解程序的编写方式,变量的意义,更能将“人类应该如何使用、会有什么样的好处”以清晰的方式展现在用户面前。而从我们已经知道的例子中,我们也能很清晰的认识到,ChatGPT也可以反向的将“人类应该如何使用”转化为程序本身。
Tom Scott将作者感受到的这种“不寒而栗”解释为“对于未知的未来的恐惧感”,以及“这次我真的不知道以后会发生什么了”的无力。作者对这种解释感受到深深的赞同,但是在赞同的同时,我们也需要通过调研、测试的方式去缓解这种恐惧。简要地来说:“未来到底会发生什么?”,“我们通过ChatGPT在这样一个未大规模使用的关键时间点,能否对未来要发生什么做出怎样的猜想?“
相信各位读者已经注意到了,上面例子中ChatGPT犯了一个小错误:这个程序一共有4个函数,但是在生成时ChatGPT说“程序定义了三个函数”。ChatGPT的这种问题并非少见,而是一个常见的,已经被使用者们称名道姓的问题。国外的Influencer称之为“Confidently incorrect”,本文的作者则将其戏称为“一本正经的胡说八道。”
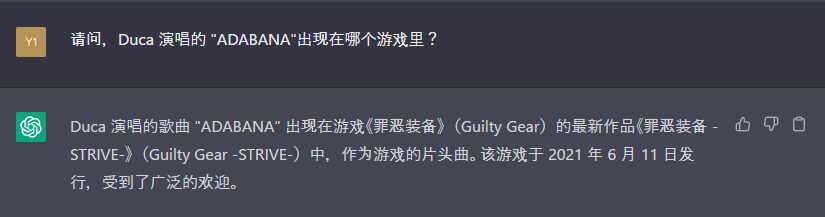
一本正经的胡说八道其一:Duca演唱的ADABANA出现在《忠臣藏46+1》作为片头曲。 “一本正经的胡说八道”,简单来说,ChatGPT有时(不是seldom,是sometimes,更有可能是usually)会生成事实错误或者逻辑错误的信息,而其表述的语气是自信的、肯定的,而不是疑惑的、不确定的。这使得用户可能会对ChatGPT生成信息的错误性不确定,甚至不知道。究其原因,这篇文章将其解释为“ChatGPT是一个被压缩了的互联网”,而其不准确性是由于压缩损失造成的。本文作者更喜欢将ChatGPT出现的这类现象归结为“知识”概念的匮乏。ChatGPT说到底还是一个极大型语言模型(LLM),本质不具备准确的逻辑推理及知识图谱库。ChatGPT对于 1+1 = 2的认识不是“1+1 = 2是对的”,而是“在大部分环境下1+1 = 2会给最后的gain function带来较大的收益”。不知道什么是“事实”,不具备逻辑性,那么势必会出现“事实错误”和“逻辑错误”。当然,也已经有业界人士意识到知识图谱对ChatGPT的重要性,但是我们还要等待这个的发展。

一本正经的胡说八道其二:尽管FalcomJDK的确是Falcom游戏音乐团队,Singa也确实代表了该游戏中相当一部分的音乐,但是Hard Desperation的作曲者是Jindo Yukihiro,而这首曲目也没有“歌词”和“演唱者”。让内行人汗颜的错误。 希望各位看官已经对ChatGPT做了自己的测试,或许各位也观察到了类似的结果。但是在“Confidently Incorrect”背后,是因为测试者能够看到ChatGPT犯下的错误(Incorrect),是因为测试者通常会选择自己熟悉的领域对其进行测试,并在感到其对自身领域可能的冲击的同时,发现ChatGPT的这样那样的不足。本文作者也是如此,论文写作、翻译、程序撰写和解释、国际象棋、历史事件的解读等等,这些是我已经具备的能力(Able)。AI在这样的场景下可以提升我的效率和能力(Boost),而我需要对其进行指导、验证和确保(Confirmation),得到本身我自己也能得到的结果(在非常快的速度下),以确保ChatGPT的最大效用。而反之,如果用户在一个自己不熟悉、不具备能力的场景(Disable)使用ChatGPT,试图让ChatGPT开拓我的能力范围(Enable),那么我有很大的可能性会陷入事实错误和逻辑错误(Falsehood),因为我本人没有能力去识别这种错误。
我们可以观察到ChatGPT可能带来的正确使用和错误使用的两个完全不同的闭环:
User: Able -> AI to: Boost -> Result: Confirmation
User: Disable -> AI to: Enable -> Result: Falsehood
这样的ABC, DEF的两个闭环其实我们可以在很多已经成熟的人工智能相关场景观测到。比如说百度/谷歌翻译,如果一个用户已经处于A的状态,那么使用谷歌翻译可以极大的提升这个人的效率,因为他能辨别翻译中的错误并修正,而如果一个用户已经处于D的状态,那么使用谷歌翻译只会让他的文章看起来一塌糊涂。换句话说,ChatGPT其实并未在这方面进行颠覆式的创新:ChatGPT仍然只具有B(oost)的功效,而没有E(nable)的效果。就如同医疗和科技的区别一样,科技可以让能处理文件的人更快的处理文件,但是不能让无法走路的人重新行走。
但是,如果没有颠覆性的创新,为什么ChatGPT会被社会如此关注?作者认为,ChatGPT其实在ABC,DEF的闭环中有着一定的“创新”,但是这种创新会带来一种致命的“幻觉”。简单来说,ChatGPT与谷歌翻译、Amazon语音等“系统”的不同,在于ChatGPT带来的B(oost)是全面性的。ChatGPT不拘泥于任何模块、系统,而是能回答用户的几乎所有问题。然而,这种全面性、几近全能性的B(oost)带来了“ChatGPT同样能够实现E(nable)”的幻觉。用户可能会如此举一反三:“如果ChatGPT能够正确的实现A-B,那么即使我在于D的状态,其也有可能实现我的B(oost)”可惜的是,实际上ChatGPT并没有脱出DEF的负性闭环,“一本正经的胡说八道”就是其最大的体现。
ChatGPT的初期负面影响总结和讨论
那么,为什么ABC、DEF这两个闭环如此重要?这就要提到ChatGPT即将面向大众的最大的产品:以Microsoft和Alphabet下属的ChatGPT和Apprentice Bard组成的“搜索引擎AI”了。
对于用户来说,搜索引擎最大的功能是什么?不是脑筋急转弯,不必多想,搜索引擎最大的功能是“搜索”,尤其是搜索“未知”的信息。思考一下,我们一般会搜索什么信息?“脱欧到底是好是坏?” “Python中如何使用yield?”“最新的显卡哪个运算速度最快?”
我们会发现,我们搜索时的问题通常是由三种问题组成的:“可由用户证实的”(1)、“可由事实证实,但是用户无法证实的”(2)、“不可由事实证实的”(3)。比如说“Python中如何使用yield”就属于(1),把网上搜索到的程序和教程拿下来测试一下就好了。“最新的显卡哪个运算速度最快?”是(2),因为我们可以通过gpubenchmark等网站获取全世界大量用户的测试结果,来佐证我们问题的结论,但是我们自己无法完全证实这个结论的正确性,因为我们手里没有所有的显卡。“脱欧到底是好是坏?” 是(3),因为这是一个复杂的问题,到现在也没有一个定论,但是我们可以搜索到足够的证据用以佐证我们自己的想法。
我们回到ABC/DEF这两个闭环。在搜索这三种问题的时候,用户分别处于什么状态,是A还是D?我们来分别进行分析:
(1)中,用户处于A(ble)的状态,因为用户即使不使用搜索引擎,也有可能通过其他方式完成搜索的问题。使用搜索引擎可以更快的得到想要的结果。
(2)中,用户处于D(isable)的状态,因为用户无法直接确认“事实”及其准确性。这种情况下,通过提供“事实”的引用链接,搜索引擎能够使用户获取到尽可能可以信任的、准确的事实。然而,这不能否定“另类事实”(Alternative Fact)的存在,以及互联网上虚假信息(Misinformation)造成的信息疫情(Infodemic)的影响。
(3)中,用户处于D(isable)的状态,因为事实并不存在,没有人或AI有能力证明不存在事实的问题。
我们可以把(2)和(3)的问题例子稍微换一下,相信各位看官就能理解正确回答这类问题的重要性。“疫苗的致死率到底有多少?疫苗有没有纳米机器人在里面?”(2)“新冠病毒到底从哪里来?”(3)
那么,ChatGPT作为一个LLM,并没有能够突破两个闭环,从而完全无法对用户提供(2)和(3)类型问题的B(oost)或者E(nable),反而更有可能引起F(alsehood)。同时,我们需要意识到另外一个问题:用户的互联网阅历(Internet Literacy)以及实际阅历越高,其对于这三类问题的分辨能力就越高,其有可能受到AI造成的F(alsehood)的影响就越小。目前测试ChatGPT的各位和“大众”之间的隔阂是非常巨大的,尽管目前来看这类问题的影响并不大,但一旦ChatGPT真的进入寻常百姓家,这种E(nable)的幻觉将会造成极度严重的影响。换句话说,目前能够测试Bingchat和ChatGPT的各位属于在“搜索”这一能力的A(ble)用户,而在“搜索”能力处于D(isable)的用户尚未实际接触到这类产品从而被其影响。
ChatGPT与AI信任危机
对于ChatGPT大众化可能造成的严重影响,相信各位看官已经有所感知。谷歌在最近的发布会上发生的错误信息丑闻是目前最大的例子,直接将其股价削掉了7%。
Apperentice Bard的耻辱墙 为什么我会提到“AI信任危机”这个词?AI被作为人类的假想敌已经在无数的文学作品中出现过了,这里不多做叙述。相信各位也被“算法”(algorithm)折磨过至少一次两次,不管是在什么场景下。在这样一个AI迅猛发展的年代,我们已经可以观察到人们对AI的不信任、甚至是恐惧。比如自动驾驶汽车迟迟无法面向大众,很大程度上也是因为这种恐惧,即使AI驾驶早已经比人类驾驶安全得多了。再比如说,医疗相关的AI,比如诊断算法,比如非接触式检测,很难实际使用在临床场景中,不止是因为人命关天,也同时是由于这样一种“恐惧”。
我们已经论证了ChatGPT可能会造成一种AI可以E(nable)用户的假象,同时这种假象会在实际大众化使用中造成严重的影响。比如虚假信息的问题,ChatGPT如果对用户提供了虚假信息,造成了人身事故,那么谁应该负责?我们可以回顾当年的“魏则西事件”,搜索引擎在其中的作用不可磨灭。同样的,在目前信息爆炸、信息疫情横行的时代,社交媒体以及其所蕴含的“算法”也占据了很大的比例。相比各位已经知道,搜索引擎和社交媒体的信任程度在大众眼中已经低到令人发指的程度。这不只是百度和谷歌大肆投放广告的作用,也同样是人类对人工智能的不信任的体现。
ChatGPT现在作为AI发展的桥头堡,势必会遭到严重的质疑,而一旦发生了大规模、高关注度的事件,那么想必人们对ChatGPT以及AI的信任将会又一次一落千丈。我们已经举了谷歌和Bard的例子,这还没有造成任何“严重的人身安全影响”呢。那么一旦出现了人身事故,又该如何?一旦出现了群体行为的改变,又该如何?
从根源上讲,作者认为ChatGPT被首先应用在搜索引擎之上本质是一个错误的选择。作为一个如此“全能”的人工智能算法,ChatGPT应该首先被应用在一个能够确保用户的能力(Ableness)的领域,而不是连人类都无法驾驭的“事实”领域。“事实”是一个流动的概念,人类社会所能认知的”Truth”是不停的变化的,而机器并没有“证实”与“证否”的能力(至少现在还是),而仅通过互联网上所存在的信息,连人类也无法进行“证实”或者“证否”。正如Tom Scott在皇家学院的“事实没有算法”的演讲中所提到,什么是真什么是假并非计算机能够处理。
作者相信,ChatGPT在搜索引擎的大规模应用,会让”事实没有算法”的这个事实更清晰的被展现在大众眼前,带动“AI是否能够被信任”的讨论。学术界对于AI的解释性和可信性的关注也会继续被提升。在这样一个关键的时间点,作者只希望,在ChatGPT造成人身事故之前,大众能够意识到AI可能带来的影响,莫要陷入了E(nable)的幻觉当中。
小结和备注
值得一提的是,ChatGPT的进化一日千丈,目前我们所叙述的很多问题,在ChatGPT大众化的时候可能会被极大程度的削弱。ChatGPT在今日从1月30日的模型换成了2月13日的模型,而很多作者遇到的问题已经被解决了。比如,1月30日的版本中,让ChatGPT去生成国际象棋棋盘的话,ChatGPT会把双方王和后的位置对调;再比如,1月30日的版本中,ChatGPT会很有信心的编造一个2021年其信息截止时还未确认的动漫作品。这两个例子,在2月13日的模组中已经被修正。
但是,这样的修正治标不治本,并未解决ChatGPT根源的问题。本文中所叙述的两个闭环、事实没有算法、AI信任危机等问题,并非通过算法学习就能够解决的问题。作者寄希望于学术界能够提出这类问题的解决方法,比如如何通过知识图谱来约束AI的行为,比如解释性AI和AI信任性的评估,等等。但是,作者更期待大众能够在“搜索”和“信息”这一方面成为A(ble)的人,然而在目前这个“信息疫情”横行的大背景下,想必各位也知道,并不是那么容易的事情。